Intro
I have found this great article How browsers work on web.dev recently explaining how browsers work in detail. I’m using this blog post to help me make notes and somewhere that I can quickly refresh the memory. If you are working on Frontend-related stuff, I strongly recommend this article as it will help you understand browsers and how they work in the background and interact with HTML, CSS, and JavaScript.
Table of contents
Open Table of contents
Role
There are many browsers out there today and you are probably heard most of them: Chrome, Firefox, Edge, and Safari etc. The main function of a browser is to present whatever resources you have requested from a server. Generally it is a HTML document (with stylesheets and JavaScript), but with browser extensions it can render files in different format like PDF.
Architecture
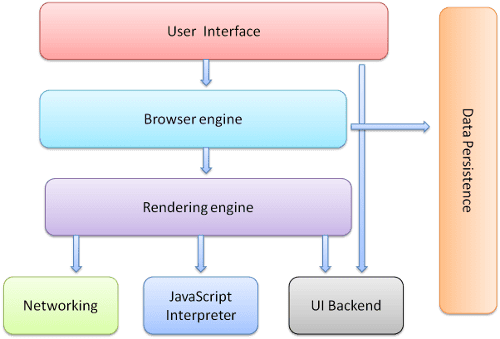 Figure: Browser’s high level structure (source: How browsers work)
Figure: Browser’s high level structure (source: How browsers work)
Let’s go through each component from top to bottom (then left to right) in the image:
- User Interface - What you see now in the browser except from the content of this page, e.g. the refresh button, address bar, and extension icons.
- Browser engine - Handle and communicate actions in between the UI and the rendering engine.
- Rendering engine - Responsible for rendering requested resources, including tasks like parsing HTML and CSS and display the content (browsers like Chrome run one rendering engine instance per tab per process).
- Networking - This component handles all networks call like HTTP requests. Implementations are platform-specific based on a platform-independent interface.
- JavaScript Interpreter - For parsing and executing JavaScript code.
- UI Backend - Used for drawing the UI.
- Data Persistence - a persistence layer for store local data such as cookies, session/local storage, IndexedDB, WebSQL and FileSystem.
The rest of the article focusing mainly on the rendering engine.
Rendering engine
The rendering engine chapter contains detail about how the engine display HTML, CSS and images. Different browsers use different engines:
- Internet Explorer - Trident
- Firefox - Gecko
- Safari - Webkit
- Chrome - Blink (a fork of WebKit)
Main flow

Figure: Rendering engine main flow (source)
A short summary of the flow:
- (Fetch data) - The rendering engine gets data (requested documents) from the networking layer in 8kB chunks.
- (Parse) - Parsing the HTML document and convert it into document object model (DOM) nodes (sounds familiar?) aka content tree or DOM tree. Styling in stylesheets (including external ones) will also be parsed into a CSS Object Model (CSSOM) tree.
- (Render Tree) - The content tree is then combine with the CSSOM tree to construct a render tree, which is the visual representation of the document in ordered tree nodes (this ensure the content is displayed in the correct order).
- (Layout) - this is a process of assigning exact coordinates of the screen to each node of the render tree so that each node is placed at the correct location according to the specified HTML and CSS styles, as well as their standards.
- (Painting) - Finally, the UI backend component goes through the render tree and “paint” each node to the user interface.
Note that different rendering engine may have slightly different terminology for each step in the flow.
Parsing
Parsers translates the document into a parse tree (representing the structure) based on syntax rules of the document.
There are two processes within parsing:
- lexical analysis - the lexer/tokeniser breakdown the input into tokens
- syntax analysis - the parser apply language syntax rules on the tokens to construct a parse tree
The following image is an example of breakdown the expression 2 + 3 - 1 into a parse tree:
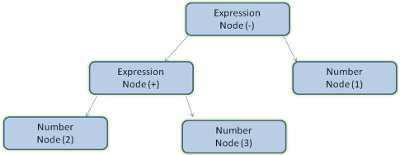
The parsing process is iterative - tokens are feed into the parser one by one and then try to find a match for the current token according to the grammar - vocabulary and syntax rules. If no rules are matched an exception will be raised, else add the token to the tree as a new node.
For more details on parsing refer to the parsing section.
HTML parser
A HTML parser is responsible for parsing the HTML markup into a parse tree. Refer to W3C HTML specification for HTML’s vocabulary and syntax rules.
The conventional parsers (discussed above) do not apply to HTML but they do work for CSS and JavaScript, this is because the grammar for HTML is not context-free grammar, and that’s why HTML still can render the document even if you missed some opening or closing tags. Given the amount of HTML pages around the world and the flexibility they have, it is extremely difficult and inconvenience to come up a CFG for HTML to use in browsers. In addition, this behaviour also means HTML can not be parsed using regular top bottom or bottom top parsers. See this section and beyond to know more details of how browser parse HTML into a DOM tree.
CSS parser
CSS can be parsed using context free grammar parsers, since there are already well defined rule sets for CSS.
Order of processing scripts and stylesheets
Scripts (with the <script> tag) will be executed as soon as it is reached, if it is hosted somewhere else then it will be fetched from the network. The parsing process halts until the script is executed. There are two ways to prevent the halting behaviour:
- Set
deferon the script, in which the script will be executed after parsing. - Mark the script async in HTML so it would get parsed and executed on a different thread.
Webkit and Firefox does an optimisation called speculative parsing where parsing and script execution are separated (off-load) to different threads for overall performance. This optimisation is only performed on external resources and doesn’t modify the DOM tree.
We can manipulate CSS using JavaScript therefore styles must be ready during the document parsing stage. Different browser has different strategy:
- Firefox - block all scripts until all stylesheets are loaded
- WebKit - block scripts only if the required styles is not ready
Render tree
The render tree (what you see in the browser inspector) is constructed alongside the DOM tree, it is a visual representation of the document which allows the browser to draw the elements defined in the document, and calculate the drawing position for each element depending on the page size. This means any changes to any attribute of the HTML elements will trigger the browser to re-render the entire DOM tree, which is a very expensive and slow operation (CPU-intensive) if a lot of updates are required.
Frameworks
To avoid re-render everything in the DOM tree, many notable frontend libraries and frameworks are introduced and trying to solve this problem:
- React - Implemented a concept called virtual DOM which keeps a snapshot of the DOM tree in memory and any state change will trigger the generation of a new virtual DOM. React will compare the current virtual DOM with the real DOM, and calculate the difference. Any changes made to the virtual DOM will then reflected on the specific part of the real DOM tree later, without re-render the whole tree. The sync process between the virtual and the real DOM is called reconciliation.
- Angular - Also uses virtual DOM initially then moved to an additional concept called Incremental DOM. This technique does not create a in-memory virtual DOM tree but working on the real DOM tree directly at the expense of some speed to gain the advantage of less memory usage (which benefits mobile devices). The main idea is to compile the template (
.htmlfile) into a set of functions/instructions (as you would found in the repo) which builds and/or updates the current component of the app. - Vue - Similar to React it implemented virtual DOM, but in addition to JSX it have templates which are also compiled into the virtual DOM render functions.
- Svelte - a relatively new framework which itself is a compiler that compiles components into JavaScript code during the build time and perform manipulation directly on the real DOM. However, this approach requires reassignment of references in order for the compiler to pick up these changes.
- SolidJS - Heavily inspired by React’s design philosophy but does not use virtual DOM. The idea is similar to Svelte - compile and transform templates into real DOM, which makes it one of most performant libraries/frameworks.
The relationship between the render tree and the DOM tree is not one-to-one, e.g. elements with display: none will not appear in the render tree.
Frames (Firefox) or renderer (WebKit) knows how to lay out and paint itself and its children, this is because each renderer represents a rectangular area corresponding to a node’s CSS box. WebKit has a special class RenderObject for the renderer.
Style computation is a big topic, refer to the following sections:
Developer have put many efforts in style data sharing, style computation, and applying rules. Firefox have two trees for managing style context and style computation, where one is for rules, and the other one divides style contexts into structs containing styles for a particular category, e.g. div. Children of these structs inherits styles and only contains styles that are not in the parent node - saving memory as well as easy to construct a path from bottom of the tree all the way to the top.
Layout
Layout/reflow is the calculation of position and size for renderer when it is added to the tree.
HTML uses a flow based layout model which can compute these values in almost one iteration, though HTML tables can require more iterations.
Layout can be proceed left-to-right and top-to-bottom. The coordinate system is relative to the root frame and starts from top left (you might find this familar if you have used D3.JS before).
The process starts from the root renderer (html tag) and iteratively perform calculation for all renderers.
Painting
This stage uses the UI infrastructure component and traverse the render tree and call the paint() method of renderer for display content on the screen.